.jpg)

The job of a risk analyst covers a critical function that can be augmented through artificial intelligence. Firms hire these individuals to accurately assess a variety of risks related to the activities conducted by counterparties. Let's focus on how firms can improve the speed and accuracy of identifying appropriate risk.
We know it's common for firms to create a high profile list of who or what to monitor and spend a majority of their time and effort monitoring these specific counterparties. Less focus is placed on the counterparties that fall outside of this list, and firms usually resort to a rotation and/or sampling strategy for the remainder. This strategy is capped by how much content a risk analyst can consume and review over a period of time. Making decisions based off of how quickly and accurately an analyst can read and ingest in a day, week or month isn't efficient and can also undermine efficacy of an organization's growth strategy.
While web crawling and robotic process automation have their strengths - and a simple Ctrl F works, too - natural language processing is a better option for individuals and firms to make headway when dealing with unstructured text. By using named entity recognition, dependency parsing and phrase/pattern matching, firms can systematically review and filter content that's relevant to a specific risk monitoring purpose. The intent is to shorten longer pieces of text and create a summary where only the relevant information is highlighted in a document - text summarization.
Jesse Sommerfeld, Head of Data Science at Kingland, says there are two main ways to approach text summarization. Utilizing an extractive method attempts to identify the most important phrasing (e.g. sentences) in content, while an abstractive method attempts to generate new text to represent its original input. He recommends an extractive method for risk monitoring; in order to do this, a mechanism is needed to rank each sentence by its importance. Humans, especially subject matter experts, are very good at recognizing important information, but this is quite challenging for a machine.
Taking a page out of Google's PageRank, Sommerfeld suggests applying this conceptually to words in sentences referencing words in other sentences. This assumes that if a word is mentioned quite often, it is likely important; likewise if the focus sentence has that word, it is more likely to be important as well. There are some inherent issues with this assumption, most of which can be overcome with pre-processing the content, and/or leveraging an Inverse Document Frequency to understand how common the language is across documents.
We can use this approach to automate the summarization of an example SEC Administrative Filing, which proves to be an overall great source for risk monitoring intelligence:
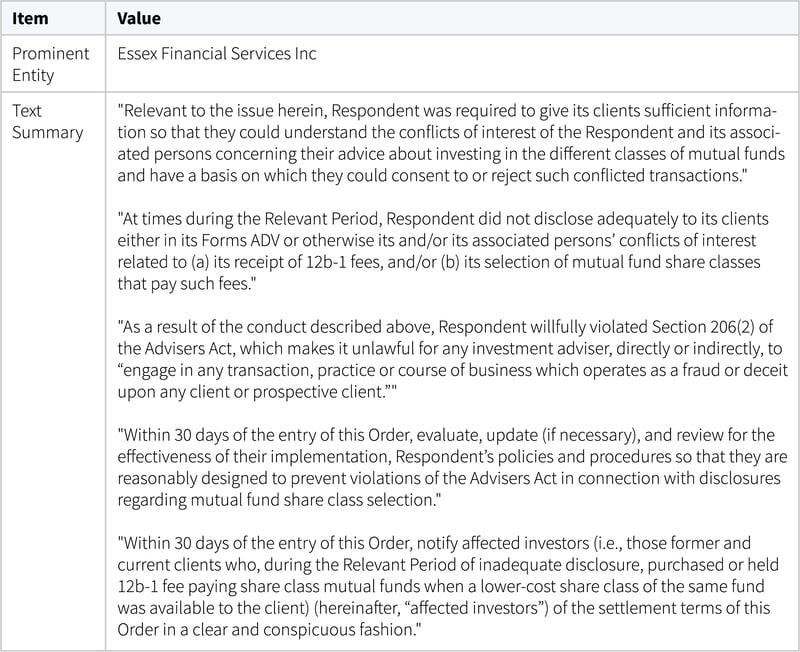
When you combine this text summarizing technique with organization, people, and event monitoring, risk analysts can accurately monitor risk for a larger set of counterparties. Sommerfeld says this allows firms to understand their risk position more completely and accurately than ever before and poses the question - what if every counterparty could fit in the high profile list?







No Comments Yet
Let us know what you think