

In the latter part of the 2000s, when the hype for AI and machine learning technology was overtaking industry and general news, Kingland embarked on a journey to automate how companies could use data to connect with what's important to them.
"Our goal was to automate the process of finding actionable content on news sites, corporate websites, and within regulatory filings," said Kingland Chief Technology Evangelist Matt Good. "Doing so would help inform downstream decisions of data management for our clients."
The actionable content Good references is important news such as a merger or acquisition that occurs with an important organization or entity. The event triggers a data management process where the data for the affected organization needs to be updated. To teach machines to read, Kingland started by employing teams of Data Research Analysts (DRA) to review data from feeds, websites, filings, and even employed a group of DRAs to read newspapers every day.
During the days of AI hype and Big Data, Kingland took advantage of distributed  processing on Hadoop because it provided the ability to process crawled content at high scale, without having to do it manually with DRAs, said Good.
processing on Hadoop because it provided the ability to process crawled content at high scale, without having to do it manually with DRAs, said Good.
Around 2009, the the early, immature days of cloud computing, the team leveraged on-premise server instances in the Kingland data center to process the content.
"Compared to our capabilities today, the ability of our algorithms in finding relevant information was pretty basic, but it was advanced for its time," he said. The team used early versions of the Natural Language Toolkit and regular expression capabilities to perform advanced word and phrase-matching to detect if the content contained relevant information.
Leveraging more than 200 keywords to help search for important events, the solution crawled content and searched for just under 100,000 entities for its clients. As was the case for most early entrants in machine learning technology, the solution still had a ways to go with accuracy.
Good says the team had to sort through a lot of noise and false positives as the solution's accuracy measured around 20 percent. He said the accuracy rate at that time was worth investing in the solution due to the automation, infinite compute power and savings the cloud provided.
Searching for Enlightenment
"The promise of machine learning started to match the hype," said Chief Technology Officer Jason Toyne. "Our continued investments in cloud, improvements in distributed processing capabilities and advanced AI modeling helped us reduce the noise and clutter for DRA processing." Toyne, Good and the team, who would talk internally and incessantly about the ML solution to anyone who would listen, were seeing the possibilities.
The company's database of entities that were important in the markets grew beyond 400,000, keywords for important events peaked around 300 and the solution was crawling and sorting around 45,000 sources. Accuracy ticked up, but not enough for the team to get too excited about their progress. Good's team injected neural network modeling to improve how well the engines would predict which content would contain actionable information. But the DRAs were still wading through a lot of noise.
During this time, the team developed cognitive personas to draw a parallel between how humans think and how the team would design future machine learning capabilities in the platform. Starting with The Collector, a persona that collects as much useful and valuable information as possible, the team thoroughly broke down the ML solution into four groupings - Collector, Scholar, Inventor and CEO. Central to the persona idea was a high-level view of how each one interacted in concert with each other and the data lake.
A series of machine learning steps (neural network) occur to determine which results the system is confident that it has relevant information for a specific task. When retrieving data, the machine combs sites for information. NLP and segmentation are used to gather data from regulatory sites and news organizations, for example. The engine is looking for specific event and company combinations to determine if or when an action is happening. Once discovered, the information is passed to DRAs who confirm whether the targeted action took place. The results of the DRA actions are fed back into the neural network, repeating this process to help the machines constantly learn and improve.
When Hype Meets Reality
Heading into 2018, the team's results and enthusiasm were picking up steam. Text Analytics was the buzzword du jour and the team was hopeful. Kingland had invested in processing architecture, language technology and algorithms to increase the accuracy of the solution. Improved algorithms increased how well the engines could find events within content that mattered in relation to the entities Kingland clients cared about.
The difference from where the team began to where it is now shows astronomic growth in a short time period. Good references the engines ability to understand context as a driver for the growth in accuracy. "We created specialized and targeted implementations of machine learning algorithms. For example, in the financial services market, instead of using a machine learning engine that can read documents and find important pieces inside documents," he said, "we've created one that knows this is a mutual fund prospectus, it understands there are four tranches inside that mutual fund, and identifies the payment structures within those mutual funds."
One client, DTCC, experienced an accuracy rate exceeding 99 percent - tracking, extracting and updating data from the SEC EDGAR document repository in real time.
DTCC "automated its data sourcing, boosting from 4 million to 5 million the number of data points covered by their database, and streamlined their clients' collection and sharing of this data, said Gordon Sands, IT executive director, IT architecture at DTCC.
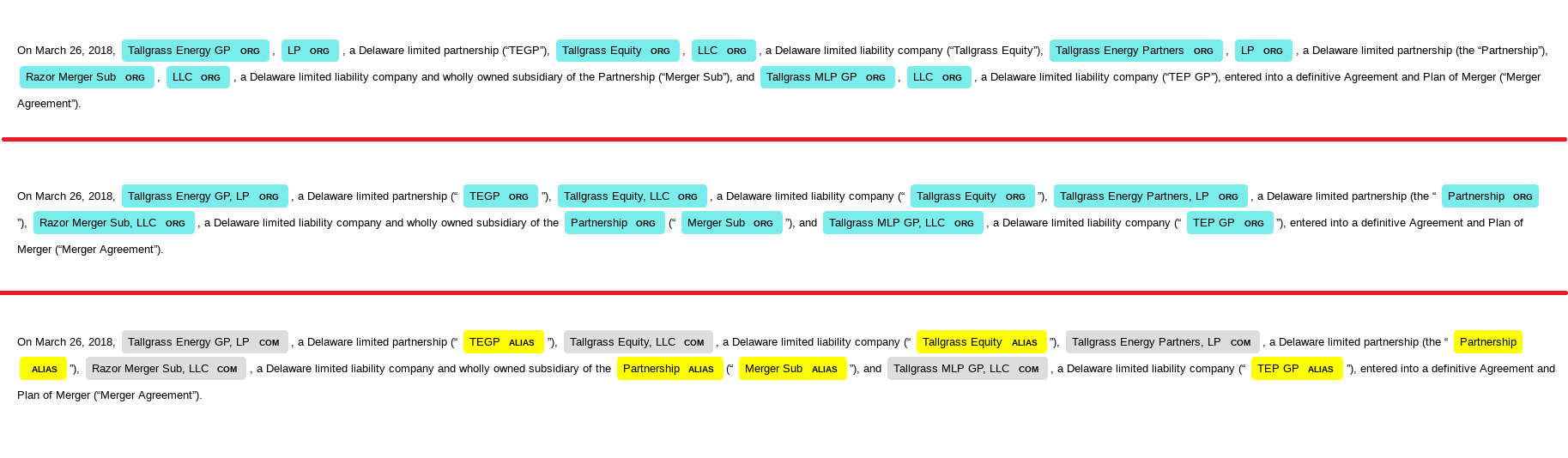
The image above shows the evolution of Kingland's machine learning technology. The lines of content - from top to bottom - progressively show how well the engine starts to understand, identify, and share what information is important according to the needs of the client. In this example, the technology needed to accurately identify all references to company names. The difference in accuracy went from approximately 32% to greater than 95%. The team initially used a generic language model before applying more targeted language models. Using Named Entity Recognition to identify sub-strings as named entities and accurately classify was an important step to increase accuracy."
As Toyne, Good and others spoke with more clients, they could see how text analytics was going to drastically improve how companies collect and make sense of their data for competitive advantage.
"The key to all of this is that we've architected and developed a platform that allows for execution of the latest NLP/NER technology at a high scale and on tons of content," Toyne said. "We can significantly amplify the amount of entities that we care about, the events we're searching for, the sources that we process, and the accuracy is proving to be well ahead of where we originally thought it would be."
As organizations focus on using machine learning technologies to reveal more insights from extensive data analysis, Toyne, Good and the team plan on helping organizations accurately connect data insight to their most important entities, people, products and more.






No Comments Yet
Let us know what you think