

At Kingland, we see a variety of challenges facing our customers. We also employ a variety of software technology and techniques necessary to meet those challenges. In recent years we've seen more and more problems around text processing, resulting in heavier use of technology and techniques within the Text Analytics space.
Though Text Analytics is not conceptually new, the rapid expansion of unstructured text has and will continue to push organizations to employ its value in order to meet their business goals. At Kingland, a common use case is to leverage Text Analytics to power Machine Learning (ML) within the Scholar persona and components from our Kingland Text Analytics capabilities. This is accomplished by breaking the text down into features that can be leveraged by an ML model.
But as the age old saying goes, talk is cheap - let's see it in action!
Let's say you have over 1 million customers and you need to correctly classify their Line of Business (LoB) for reporting purposes. Sure, you already staff a team of data/subject matter expert analysts that can do this manually, but you need this completed in six months. So you staff up, train more team members, and try to power through it.
Your downstream consumers start seeing inconsistencies and quality problems with the manually classified customer data records, and you have even more customers being on-boarded every day, making it seem impossible to keep up. You start asking questions about automation, but your team lacks the skill-set and capacity to make sweeping changes to the process needed for operationalizing the vision. Sound familiar?
This is a common situation organizations find themselves in. Truth be told we've been there ourselves. We invested in an ecosystem to help solve the problem, and subsequently built it into our Kingland Text Analytics capabilities.
There are many ways to start tackling a problem like this, but first let's do our homework on what makes a human expert "good" at performing this task. What's especially useful to understand is the difference between the new trainee and the superstar data analyst for this (manual) work, then we'll discuss some application methods.
Don't let the name fool you, Cognitive Biases are developed over time and are not always bad. True, they can distort consistency and accuracy when switching context or fields of study, but those same patterns can provide practical value through experience. When your superstar data analyst sees something, their biases are engaged whether they know it or not. When training an ML algorithm it will inherit bias based on the training material it is provided. The key is understanding when this is acceptable to leverage, while understanding that in most practical applications this is something you will be unlikely to avoid altogether. The real question is whether you want your superstar to be scalable, or if you're looking to identify new insights from your data.
Supervised Learning is a very popular method of training a classifier where we have a host of labeled training data available. A classifier maps input data into a category. This method is also typically favored when one prefers interpretable over "black box" algorithms (e.g. you want to know what features and at what weight on influence they had on output).
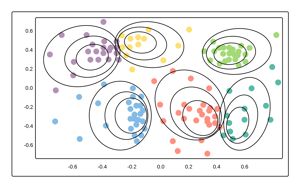
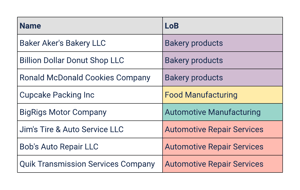
A multitude of nuance exists when developing a classifier, such as unbalanced classes in the training set (i.e. many training examples of few classes with limited examples of others), but can be combated with careful consideration. In all, this method can be a practical approach to solving the classification problem introduced above and can fit your classifier to your specific schema.
For all the flack Unsupervised Learning receives in the war of interpretability, it's an extremely useful tool when you lack labeled training data. The core concept is to train a model to group a set of data into factions that are more similar to each other than those in other factions.
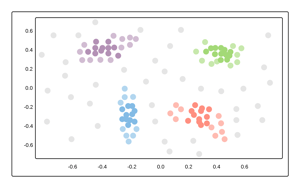
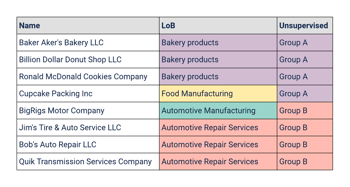
Using this method, the model develops its own view of the data, which can assist with combating biases that exist in a labeled training set, while introducing new challenges such as fitting natural clusters into prescribed schema. This is still a valid method to employ when attempting to solve the classification problem above.
For real problems with real data, a hybrid or ensemble approach is often required to get the results you're looking for. There is no algorithm that rules them all, which is especially true when you're working outside of a lab. Leveraging an ensemble methodology, at Kingland we've seen a 250% increase in efficiency in this classification problem, rapidly accelerating time-to-market and consistency. We first implemented a sound data management process where data research analysts would research each customer entity to manually apply the entity's classification. In parallel, our AI team worked on the Supervised Classifier and Unsupervised Clustering ensemble approach for providing automation to this manual process. As we crossed over the 50,000 mark for customer entities manually classified, we began to have enough data to facilitate the automation to a degree of accuracy we expected - first with automating the manual classification review process (e.g. if the models and algorithms produced the same classification suggestion as the manual research, the manual review could be skipped), and next with automating more of the classification process overall, once the accuracy of the models met expectations.
This overall approach - leveraging manual data research processes with accompanying and increasingly accurate automation through Text Analytics and ML - allowed us to scale our superstar data analysts, so that we could take on more customer entities in the classification problem, or otherwise apply their efforts to additional projects.






No Comments Yet
Let us know what you think